Dr. Shaikh: Talking the Talk


Many of our homes today feature devices we verbally ask to tell us the time, play music or turn on the TV, but interactions with conversational assistants remain limited. Now imagine if your Siri, Alexa or Google Home could talk with you, detect, interpret, and react to linguistic changes throughout the conversation.
Assistant Professor Samira Shaikh with both the Department of Computer Science in the College of Computing and Informatics and the Department of Psychology in the College of Liberal Arts and Sciences. She is also an affiliate faculty member of the School of Data Science. Her team employs high-performance computing to study and improve how our communication tools, like conversational assistants, use language models, dialogue agents and text classification.
Dr. Samira Shaikh directs the SoLID lab at UNC Charlotte.
Earth to Alexa
Conversational assistants rely heavily on language models for both natural language processing and understanding. To encode nuances of natural language, including semantics, syntax and morphology, language models need to learn distributions over large amounts of data. These models must also cipher information relating to the psycholinguistics and sociolinguistic dimensions of language. Thus, language models have become central to many natural language processing tasks, such as answering questions, translating for machines and summarizing dialogue systems.
Current language models are trained on big data and require large neural models that can be pre-trained. The idea is that large pre-trained models can then be pre-fine-tuned or fine-tuned to the task at hand.
Ah, OK
One project that the SoLID team is working on is creating Cognitive Architectures for Conversational Systems. Automatic generation of natural language entails not only incorporating fundamental aspects of artificial intelligence but also cognitive science. Extant approaches to natural language generation have typically been formulated as sequence-to-sequence frameworks, an adaptation of machine translation systems. Prior research has shown that engaging with these systems for more prolonged interactions could result in dull and generic responses from the conversational system. One reason for this is their reliance on the last utterance in the dialogue history as contextual information. To make better use of context, researchers have used both hierarchical and non-hierarchical neural models. However, these models still suffer from suboptimal performance due to the inclusion of the entire dialogue history containing irrelevant expressions.
The central question we aim to address is this: How do we encode more context into the natural language system so the algorithm can focus on essential topics while appropriately discounting parts that may primarily serve to preserve social conventions (e.g., “ah” and “OK”)?
To address this challenge, Dr. Shaikh and her researchers take a cognitive science approach. They rely on an adaptation of the Standard Model of Cognition, an established memory model in cognitive science. The model provides the framework to conceptually and practically address both long-term memory and short-term memory (working memory) to incorporate the extended context of conversation along with the immediate context. In addition, the model provides a novel action-selection mechanism acting as a bridge between the long- and short-term memory.
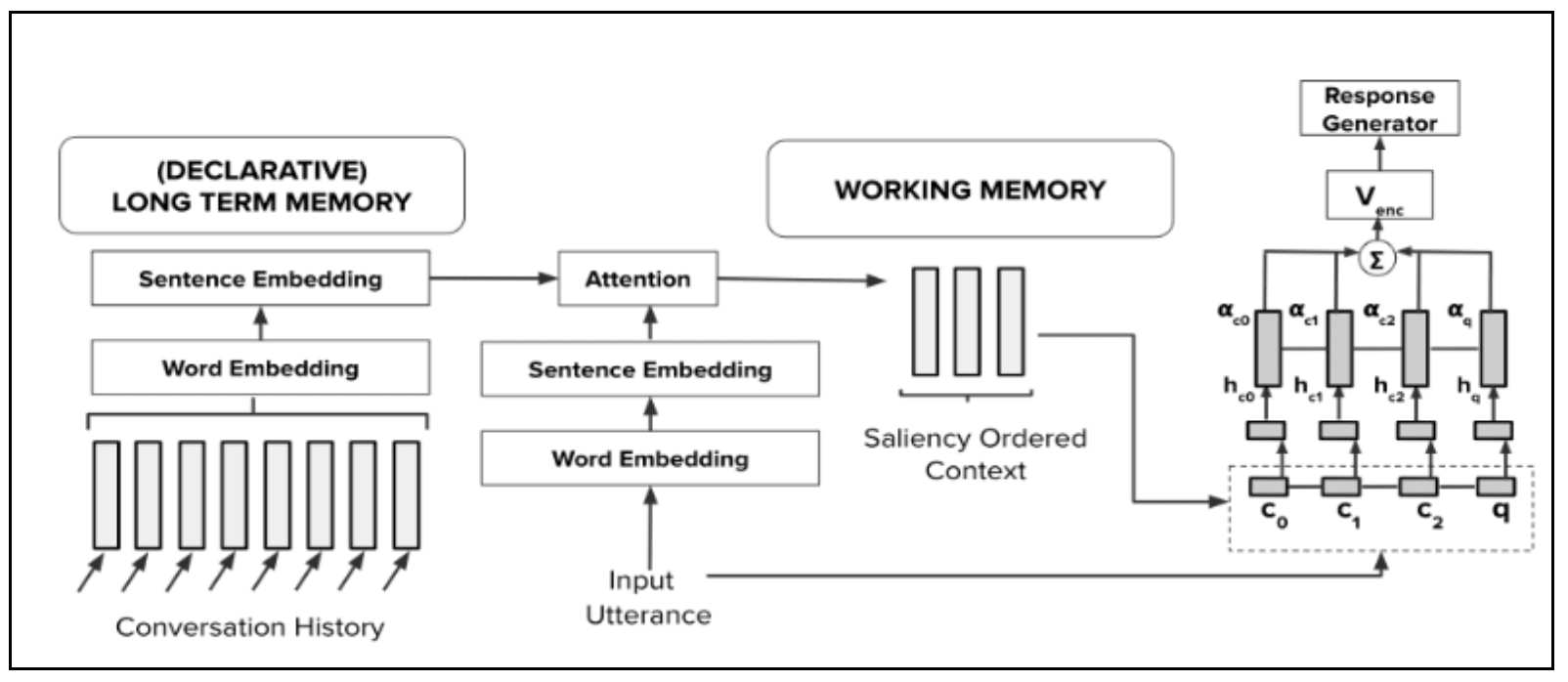
Dr. Shaikh et al. utilized several graphics processing units in the high-performance computing environment at once for this project. Unlike a standard computer, each GPU can perform thousands of operations in tandem, allowing her team to handle larger batch sizes and train transformer-based dialogue state tracking models.
Figure Caption: Dr. Shaikh and her team track dialogue states to better understand the user’s intents while speaking to a conversational agent. The team believes their work is the first to use the standard model of cognition to more closely tie the natural language generation system to the way human cognition works.
To the Point
Another project is task-oriented dialogue agents. Dr. Shaikh’s team is involved in developing a neuro-symbolic system for general task-oriented dialogue for the Air Force Research Lab. This system, known as ATICA, addresses interactive question-answering with an intelligent dialogue agent for Air Force analysts. ATICA is innovative, using deep learning technologies (transformer models) to learn how to generate dialogue plans (i.e., semantic and pragmatic structures) representing the analysts’ goals and intentions and their impact on the ongoing conversation.
Each interaction starts with a user-specified task, such as a question or request. At each step, the system either returns an answer or generates a query to the user to clarify the meaning, correct misunderstandings, make a suggestion or request additional information. ATICA learns from four types of information: (1) the input utterance; (2) its semantic-pragmatic plan, i.e., the plan used to produce the utterance; (3) the history of interaction and (4) the available structured and unstructured knowledge sources. Further, with the use of a semantic-pragmatic plan representation and the cumulative history of the dialogue, Dr. Shaikh captures the evolving state of the parties’ objectives in a condensed form. When relevant structured knowledge sources exist, the semantic structure is grounded to the ontology so that the following utterance is supported by inference from data.

Crucially, the evolving dialogue state includes the progression function, which tracks the interaction progress towards a successful conclusion, a critical step toward an aware AI agent. The progression function combines direct feedback from the generated dialogue moves (i.e., evidence of provided answers in the ontology) with indirect feedback inferred by the users’ reply. The system adjusts its interaction strategy and the choice of arguments based on the current dialogue state (e.g., the missing information for determining the answer or the user probing for a better solution). ATICA does not rely on a prescribed set of options or hand-coded scripts; instead, it learns and ranks several possible dialogue moves to meet the analyst’s objectives best.
Figure Caption: This example interaction with ATICA displays a changing dialogue. Behind the scenes, ATICA maps out responses and adjusts to the conversation to meet an outcome.
Ethical Dialogue
Propaganda is an expression deliberately designed to influence the opinions or actions of others to meet predetermined ends. Once exclusive to big institutions like governments and corporations, propaganda is now available to anyone on the internet or social media. In addition, algorithms and automation decrease the cost to generate and distribute propaganda content, enabling a significant domestic and international reach. For example, it is estimated that bots generated 19% of election-related tweets in the 2016 US presidential election. Given the potential for influence, propaganda must be detectable by conversational assistants.
A set of persuasive techniques are adopted to create propaganda content, including black-and-white fallacy, whataboutism, red herring and strawman. One direction of the SoLID team’s research is identifying the persuasive techniques used to generate propaganda content. In this project, Dr. Shaikh and her team have worked to detect (1) propaganda techniques used at the sentence level and (2) specific spans that use a particular propaganda technique.
Modern text classification tasks are based on pre-trained transformers like RoBERTa and BERT, a large model with 110 million parameters. Dr. Shaikh’s team tried different models, including BERT-cased, BERT-uncased, RoBERTa and fine-tuned RoBERTa. In the end, the team again needed the high-performance computing environment for graphic processing units and to partition data for processing.
In addition to propaganda, the proliferation of hate speech on social media has drawn massive attention in academics because of the potential for profound and far-reaching social influence. A social networking service known as Gab lacks the hate speech regulation of comparable platforms and shows a higher percentage of hate speech and toxicity rate.
Dr. Shaikh and her team created a new, pre-trained model based on RoBERTa to detect hate speech on Gab. First, they fine-tuned the original RoBERTa model on the Gab corpus with the task of the masked language model to predict randomly masked tokens in a sentence to gain more knowledge of hate speech. Then, researchers used this pre-trained model, named as GRoBERTa, for several related hate speech detection tasks: (1) Offensive Language Detection (Is the text offensive or not offensive?); (2) Automatic Categorization of Offense Types (Is the offensive text targeted toward a group or individual or untargeted?) (3) Offense Target Identification (Who or what is the target of the offensive content?) and (4) Personal Attack Detection (Is there personal attack in the posts?).
The original dataset of Gab posts consists of 9.64 million posts. The fine-tuning process and different downstream hate speech detection tasks required multiple GPUs. As computational needs for the project were well beyond a typical machine, the team utilized the high-performance computing environment to store and process terabytes of Twitter data on multiple processors and RAM.
In Conclusion
The human ability to communicate using natural language is truly unique. Faithful replication of the human-like ability to understand and use natural language by machines is one of the next frontiers toward achieving Artificial General Intelligence. Through this work and with the high-performance computing capabilities, Dr. Shaikh and her SoLID team attempt to push the boundaries of that frontier.